The Flex Parser API helps you extract key information from messy or structured data — like HTML, JSON, XML, CSV, or plain text — using simple instructions written in natural language.
Just tell the API what you want to extract, and it will use AI to understand and return the data in clean JSON format.
What Can It Parse?
- Emails or newsletters
- JSON payloads (e.g. from webhooks)
- XML feeds
- CSV files
- Invoices, logs, or plain text
When to Use It
Use this API when:
- You want to extract values like names, prices, dates, or contact info.
- The content is too messy or inconsistent for regular parsing tools.
- You prefer to describe what you want, instead of writing complex rules.
API Endpoint
- Method:
POST - URL:
https://node.nodetrigger.com/api/flex-parser - Headers:
Content-Type: application/json
Request Body
{
"type": "html | json | xml | csv | text",
"data": "<your base64-encoded content>",
"context": "What you want to extract (in natural language)",
"fields": "optional, comma-separated list of field names"
}
🔐 Make sure to encode your content in base64 to avoid format issues. Most tools like Make.com have a “Text to Base64” function.
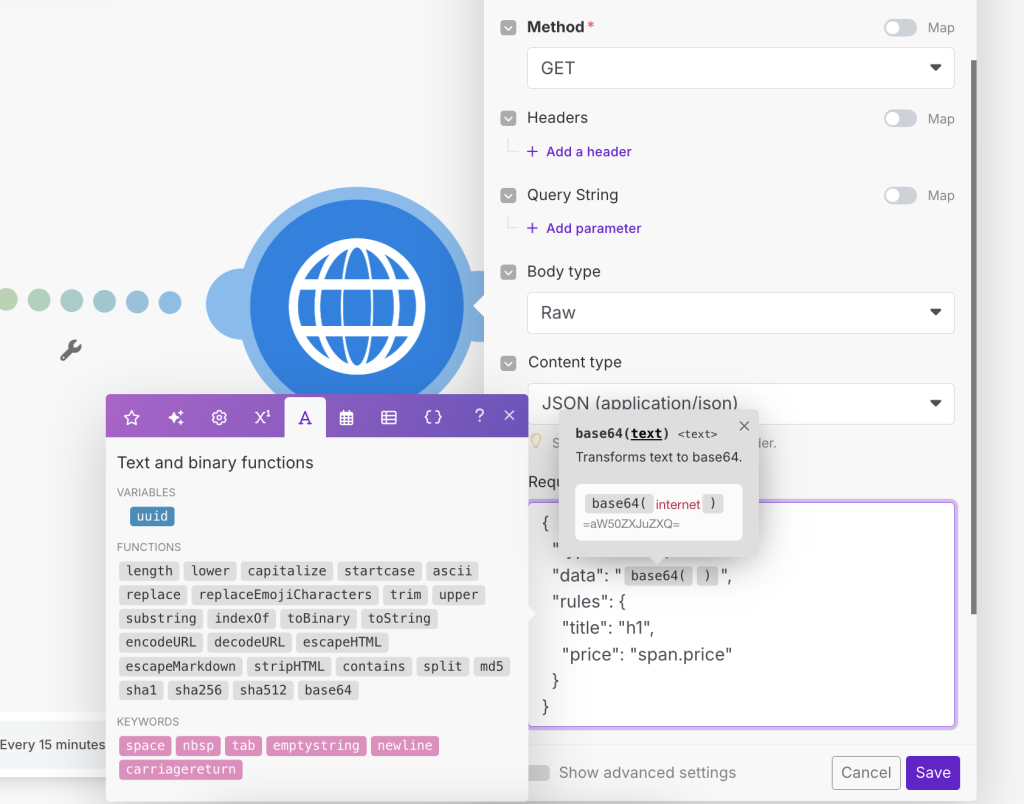
Custom Field Names (Optional)
You can provide a list of field names you’d like the output to follow using the fields parameter. This helps ensure the response uses your preferred naming.
Example:
{
"data": "base64...",
"context": "Extract direct phone number, name of the company, and address",
"fields": "phone_number,name,address"
}
Response:
{
"result": {
"phone_number": "03 83 00 45 99",
"name": "Cloud Team",
"address": "78, rue de la gare, 54320 Maxéville"
},
"confidence": 1
}
If the AI can’t confidently find a field, it will skip it — no empty or fake data.
Confidence Score
The response includes a confidence value ranging from 0 to 1 (High), depending on how many of your requested fields were successfully extracted:
1means all fields were found0.66means 2 out of 3 were found0means no usable fields were extracted
Use this score to decide whether to trust the result or fall back to manual review.
Quick Example
Say you have an HTML email like this:
<div><h1>Order Confirmed</h1><span class="price">$29.99</span></div>
Request:
{
"type": "html",
"data": "PGRp...etc",
"context": "Extract the order title and the price"
}
Response:
{
"result": {
"title": "Order Confirmed",
"price": "$29.99"
},
"confidence": 1
}
Input Size Limit
To ensure fair usage and prevent abuse, our Parser Node enforces a maximum input size of 30,000 characters (after decoding your base64 content). This limit is sufficient for most use cases like parsing email templates, JSON payloads, or structured documents. If your content exceeds this limit, the API will return a 413 Payload Too Large error. Please make sure to keep your input concise and focused on the relevant content you want to extract.
Tips
| Issue | Solution |
|---|---|
| Raw text breaks the request | Always use base64 to encode the input |
| Missing values | Refine your context to be clearer |
| Unsure what to write | Just describe what you need in plain English |
| I get “413 Payload Too Large” | The data you try to parse is to big. Try to keep your input as concise as possible. |
Need Help?
Send us:
- Your data (HTML, text, etc.)
- What you want to extract (e.g. “email address, product name”)
We’ll help you craft the right request.