Have you ever wished you could effortlessly extract valuable data from websites without diving into complex coding?
Webscraping can be a game-changer in automation and data collection, providing you with the tools to gather information seamlessly and efficiently.
Understanding the Webscraping Node
Our webscraping node allows you to add simple HTML scraping mechanisms into your automation processes in Make.com. Our module enables you to extract valuable data from websites without complex coding or manual intervention. By leveraging this node, you can initiate HTML scraping requests to retrieve specific elements from web pages.
The webscraping node requires the following parameters:
- url (required): The URL of the website to scrape.
- key (required): Your unique API key for authorization.
- selector (optional): The XPath selector to target specific elements in the HTML content.
- regex (optional): Regex pattern you want to use to extract elements on the page.
Setting Up Your Webscraping Node
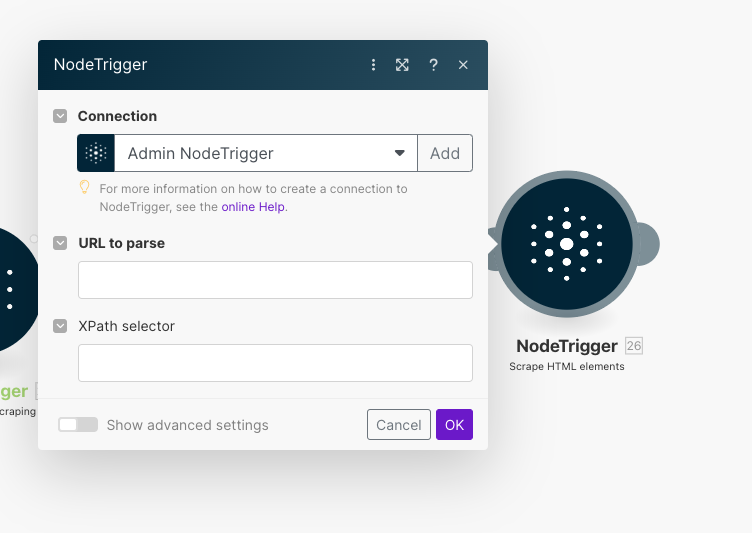
To set up your webscraping node, you need to understand the importance of each parameter and how they contribute to the scraping process:
- URL: This is the website address from which you want to scrape data.
- Key: Your unique API key ensures that you are authorized to use the webscraping service.
- Selector: This optional parameter allows you to target specific elements within the HTML content using XPath. XPath is a powerful tool that helps you navigate through elements and attributes in an XML document.
- Regex: If you need to extract data using pattern matching, you can provide a regex pattern. This is particularly useful for broad pattern matching across the entire HTML content.
Generating XPath for Targeted Scraping
Generating an XPath to scrape a specific element from a webpage is straightforward. Follow these simple steps:
- Open the Webpage: Start by opening the webpage in your browser where the element you want to scrape is located.
- Inspect the Element: Right-click on the element you want to scrape (like a button, text, or image) and select “Inspect” or “Inspect Element” from the context menu. This will open the browser’s Developer Tools and highlight the part of the webpage’s code that corresponds to the element.
- Navigate the Code: In the Developer Tools, you’ll see the HTML code of the webpage. The highlighted section represents the element you right-clicked on. Look at this section to understand where your element is in the code.
- Understand the Structure: Notice the hierarchy of the HTML tags. Each tag can be a parent, child, or sibling to another tag. Understanding this structure helps you pinpoint the exact location of your element.
- Copy the XPath: Right-click on the highlighted code in the Developer Tools, then select “Copy” and choose “Copy XPath.” This option gives you the XPath, which is like a map that shows the exact path to your element in the webpage’s code.
- Use the XPath: Now that you have the XPath, you can use it to tell your scraping tool exactly where to find the element. The XPath will guide the tool through the webpage’s structure to the exact spot where the element is located.
By following these steps, you can generate the XPath to accurately target any element on a webpage, making it easier to scrape the data you need.
Example Usage
Suppose you want to extract the titles of articles from a website with the URL “https://example.com” using the XPath selector “//h2[@class=’article-title’]”. Here’s how you would structure the call:
GET https://nodetrigger.com/wp-json/custom-api/v1/scrape/?url=https://example.com&selector=//h2[@class='article-title']&key=YOUR_API_KEYUpon successful execution, the API will respond with an array containing the extracted elements based on the provided XPath selector.
Practical Use Cases
The webscraping node can be applied in various scenarios, including:
- Content Aggregation: Gather specific information from websites for analysis or display. This is useful for news aggregation, monitoring competitors, or collecting reviews.
- Data Mining: Extract relevant data from web pages for research or business purposes. This can include collecting product details, pricing information, or market trends.
- Automated Content Retrieval: Retrieve structured content from websites to automate data collection processes. This can streamline workflows, such as regularly updating databases with the latest information.
- Email Extraction: Gather emails from webpages for marketing campaigns, lead generation, or customer outreach.
Conclusion
Integrating the webscraping node into your automation workflows can significantly enhance efficiency and data collection capabilities.
By understanding the parameters, generating accurate XPath selectors, and applying this tool in various use cases, you can streamline your processes and gather valuable data effortlessly.
Embrace the power of webscraping to unlock new possibilities in automation and data collection.